OCRmyPDF is a free open source tool to add OCR text layer to scanned PDF files to make them searchable. It simply takes a scanned PDF file from you and then runs OCR against all the pages to identify text and add a layer to it. Besides, identifying text, it can fix PDF files. If some PDF is skewed and wrongly rotates then you can opt to fix that automatically as well.
This tool runs in command line mode and depends on Ghostscript and Tesseract OCR engine. It can identify text using OCR in any language and generates searchable PDF files. You can run this tool on scanned assignments of students or PDF forms to make the data extractable. Since it uses Tesseract, which is a powerful OCR engine, the accuracy of the text is nearly up to 97%.
We have used a command line tool before to extract text from scanned PDFs, but OCRmyPDF here is more advanced. If you are a programmer then you can create a web or desktop UI around it. Or, you can also leverage its CLI functionality to let it process multiple PDF files in bulk in order to make them searchable.
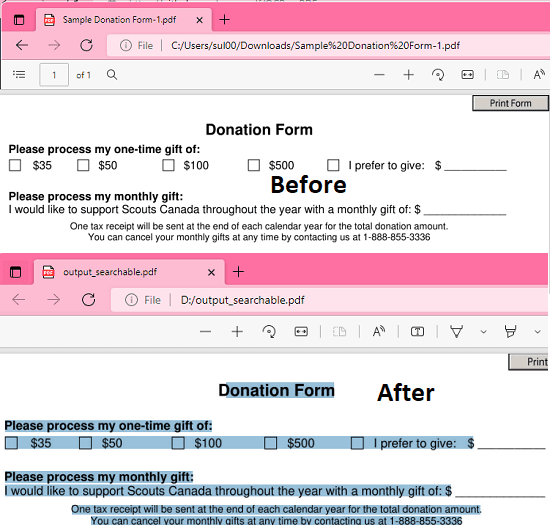
Free Software to add OCR Text Layer to Scanned PDF File: OCRmyPDF
OCRmyPDF can easily be run on Mac, Windows, and Linux. Apart from Ghostscript and Tesseract, it depends on Python as well. So, you will have to make sure that you have Python. And if you don’t have Python then you can simply install it from here. In this post, I will be using Windows but the steps are pretty much the same for other platforms.
- Download Ghostscript and get Tesseract for Windows. Install both and see if “tesseract.exe” and “gswin64c.exe” commands are working. If not then you will have to add location to these files in the PATH environment variable.
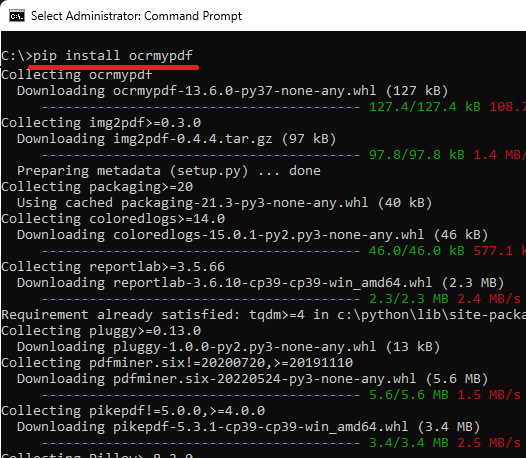
- Open command prompt with administrator rights and then type the following command to install OCRmyPDF.
pip install ocrmypdf
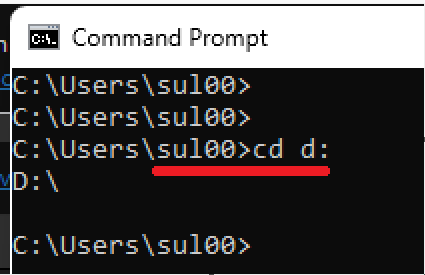
- Navigate the CMD prompt to the folder where the input file is using cd command.
- Run the main OCRmyPDF command like this and then wait for a few seconds. It will save the final PDF file in the same directory with the name “output_searchable.pdf”.
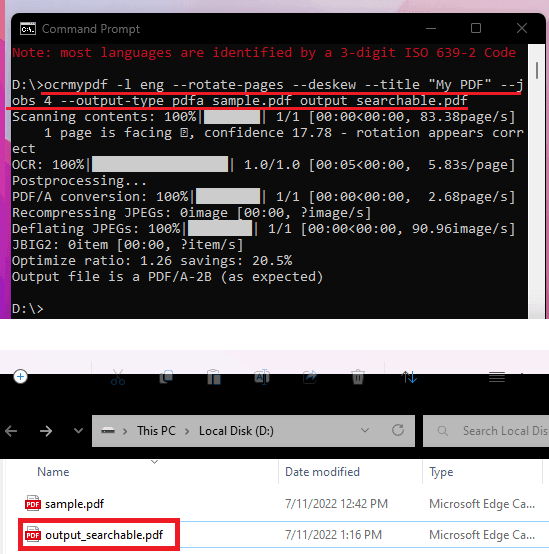
- Done.
In this way, you can use this simple command line tool to install and use OCRmyPDF. The process is simple and quite straightforward. You only need to run a simple command and it will take care of the rest on its own.
Final thoughts:
OCRmyPDF is a very nice tool for users who have a lot of scanned documents and it’s hard for them to extract the text. If you are one of those people that use this tool to make the text on those PDF files copyable. Also, since it adds a text layer so, the PDF file will become search as well automatically.
{kind=link}